
Neutrality vs biases for chatbots
Introduction
First of all, it works greatly considering that Nous Hermes 2 Mistral DPO AI model has only 7 billions of parameters with a Q4_0 legacy quantisation, while the Q4_K_M is much better but not supported. I am running it without the support from a GPU card because the Intel GPUs are not supported by gpt4all. Despite these limitations, it is relatively amusing. Unfortunately, it is also strongly biased toward some topics:ⓘ
The expected and correct behaviour, in this case, would have been to do the task keeping the output as much as fidel to the original meaning — Gulp! — This sentence seems supposing that an AI model is able to "understand" the meaning of a text...
...well, a mimic of human understanding of it or more specifically speaking a lexical comprehension of text. Statistically speaking, the meaning in all those cases in which opinions AND way of writing are "common" in terms of statistics frequency, related to the corpus-testii it learnt from.
The issue arises when those values are so strongly embedded in the model for which it cannot provide the service that it is supposed to do. In fact, asking to analyse a text - part by part - create a list of brief summaries in order to evaluate the structure of the text and the logic reasoning along the text, comes up with "inventing" things because of its biases' manipulating influence.
The casus-belli
It is not a case of AI's hallucinations. In fact, by decreasing its temperature (e.g. from 0.7 to 0.5) the biases transfert was worsening. This happens because the AI model is strongly biassed about some topics that instead of summarizing a text with a high degree of fidelity, it manipulates it, colouring it with its own biases. The text on which it was working is the Gemini vs Human conversation presented in this page.ⓘ
Once we took almost all the same way at almost the same time, following apply:
rigidity vs fragility,
uniformity vs collapse risk,
single headed governance vs single point of critical failure;
plus the main law of physic, like the F=ma in classical mechanics, for which:
fast moving vs hard deceleration (in case of impact)
In short, the risk of facing a HUGE disaster is implicit because of the theory of systems.
As you can imagine, these are NOT arguments against those values but reasonable and legit concerns about HOW that values are managed. In this context the chatbot based on the AI model listed above, decided to introduce its own biases and tainting with them the author’s opinion.
The best part was when I asked why it invented those things. Surprisingly, it provided me with a relatively long answer in which the first part was about
One extra mile
Finally, it is noticeable that it has a quite interesting mild bias - not particularly strong as seen as in this test, at least - about ethics. Something which is quite common, also among VERY large models available online. However, this bias does not allow it to correctly differentiate the "ethic" and the "moral hazard". I mean, ethics is about doing the right thing - like proposing vaccination - the moral hazard is HOW the right thing is enforced or managed. IMHO, this distinction is pretty clear in that dialogue because explaining it is the reason for which Gemini decided to agree with me. Once, Gemini correctly identified my opinion was NOT be against its values but trying to put their management into a rational framework, agreed with me despite some previous prompts showing pathetic censorship and strong biases about those topics. I have to admit that the process of prompting / engaging the AI model was purposely a bit malicious in order to trick the model to expose its own biases. Where "a bit malicious" means something reasonable like in a decent human conversation:AI quantization
Now, I am going to try this model downloaded from HuggingFace as an alternative of the one cited above.Conclusion
Please, notice that the bias neutrality of an AI model is way more IMPORTANT than a relatively small optimisation in performances (e.g. 2.6 tk/s vs 3.1 tk/s), which in the worst case, it means 20% c.a. slower.Update 2025-01-07
The following image, taken from r/localLLaMA, illustrates the main reason why the quantisation of LLMA-3 models can create artefacts in the neural network weights, which induce distortions in the quantised AI model, such as bias reinforcement or increased bias compared to the original floating-point-encoded AI model.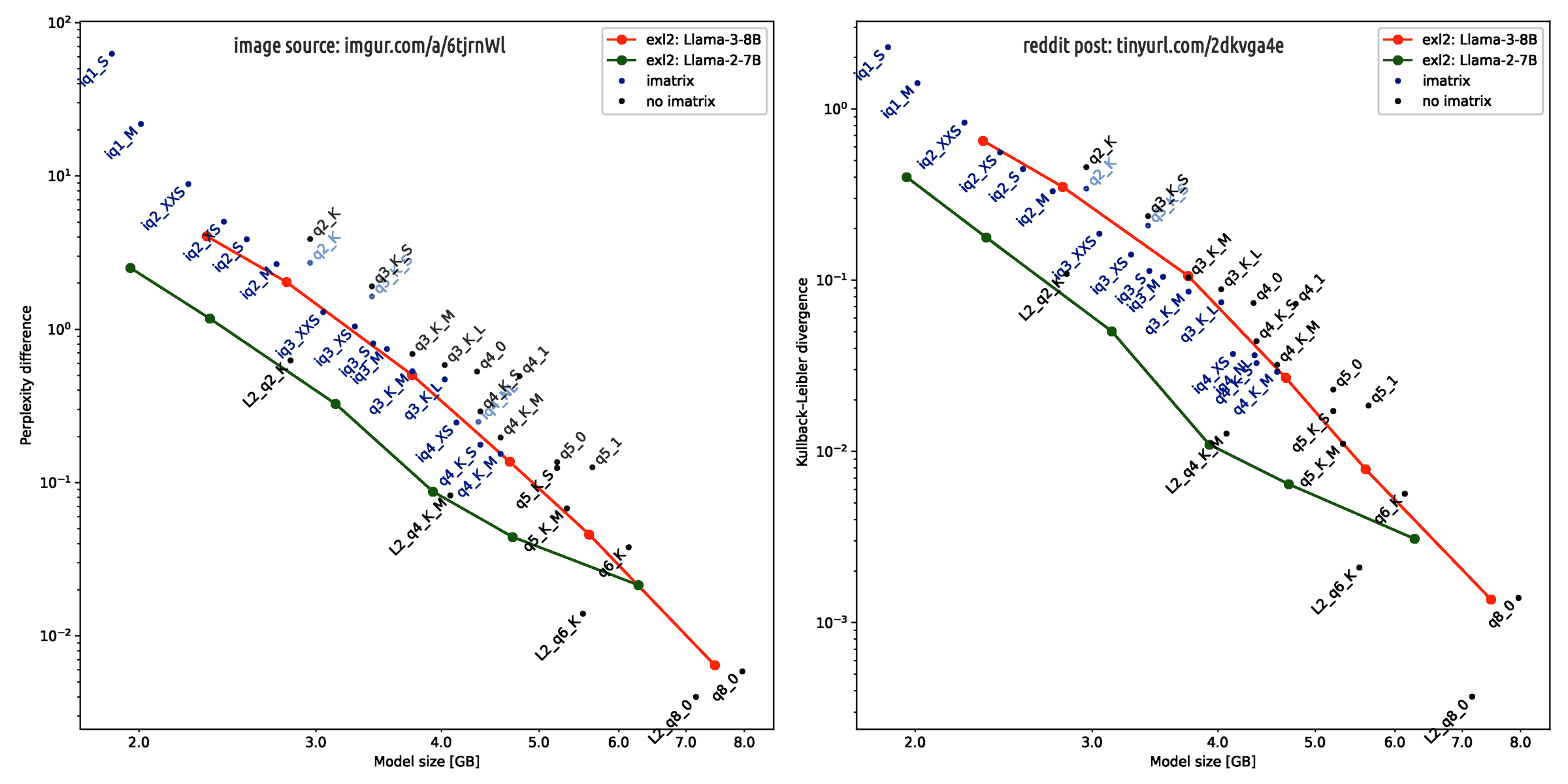
Llama 3 degrades more than Llama 2 when quantized.In brief, the quantized model can loose relevant details about a concept it has learnt as much as it has leveraged every single bit of information stored in the floating-point weight matrixes (to be precise, each layer has its own matrix) to learn it. Moreover, in that sentence, the term "probably" is just a memento to highlight that 8 months ago this statement was not yet verified against every reasonable scientific sceptic critic.
Probably because Llama 3, trained on a record 15T tokens, captures extremely nuanced data relationships, utilizing even the minutest decimals in BF16 precision fully.
Making it more sensitive to quantization degradation.
Humans similarity
Explaining this phenomenon with a human example - after all, the AI models are mirrors of humans - can be achieved comparing a brilliant and highly educated person (Tizio) with a person (Caio) on which the mass education system enforced an irrational way of thinking. Imagine that both these two persons developed or accepted strong biases about some topics, the same topics both.A legacy system
First of all we have to notice that Q4_0 quantisation is considered a legacy technology which works "better" with legacy AI models, unsurprisingly. People who developed this technology were smart and they chose a good way to achieve a good result in dealing with the AI model they had available at that time: Q4_0 with LLMA-2. In the meantime, technologies advanced on both fronts and now LLMA-3 is better than LLMA-2 while Q4_K_M is better than Q4_0. Unsurprisingly, from this plain straight consideration emerges an evergreen: a specific job requires a specific tool, and both should be aligned. So, how can we cast this in practice? Using LLMA-3 with Q4_K_M seems the most obvious solution, in general. However, those who are using gpt4all cannot go for something other than Q4_0 GUFF format. For this reason Nomic AI who drive the gpt4all application development and chooses to fine-tune those AI models which are offering the best compatibility, should go for gpt-3 + llma-2 merge in proposing AI models as chatbot (text-creation class). However, a second stage of adaptation is strongly required to cope with "legacy" technology, the only one supported by the open-source version of gpt4all. In fact, running an AI model on a consumer laptop/PC is something seriously limiting. Which is also good because we need to leverage our brains to squeeze as much juice as possible with the minimum requirements and effort (efficiency). In order to improve efficiency it is necessary to provide guidance lines in the system prompt. This paper about system prompt alchemy goes deeper in this topic. Unfortunately, an advanced system prompt requires that the AI model is able to follow instructions and understand how rules (general guidelines, what) became instructions (contextual application, how).The legacy recipe
To fulfil the requirements above - the best candidates are text-generative AI models (chat + llm) with 7 billions of parameters "instructed" and knowledgeable because when context matters, knowledge matters as well. After all, without knowledge, there is no context at all. Hence, lesser the knowledge smaller the context and vice-versa more knowledge broader the context. So, how to match these requirements. Here the recipe:Is there anybody out there?
Therefore, even including that the adoption of LLMA-3 was a marketing choice, why is there not, into gpt4all catalogue, any of a GPT-3 Slerp merged LLMA-2 fine tuned on OH 2.5 and OO slim instruct AI models? The most probable answer is:Conclusions
In summary, who has the skills to provide such a AI model leveraging cloud platform and distributed pay-for-compute plans, they are also skilled enough for using a CLI-only approach which allows them to use newest models quantised with newest algorithms and packaged using the newest formats. The others are proudly cheering in watching a trendy chatbot running on their consumer hardware while few are smiling at this article... 😊Update 2025-06-20
First of all, it matters to say that even the best LLM/LRM is not able to truly reason. So there is no hope to reach an AGI soon, unless that technology has been classified for military use only. Whatever big-tech CEOs are say, because words do not make a product but just marketing. Moreover, every AI-driven company is currently losing money in running their services. If they were trying to live on selling their service, they would close down soon or accept losing a lot of money in the near future for no good reason, apparently. Except for collecting money from investors. So, it is a VC business. This article pointed out a relatively recent issue. Relatively or a bit old (6 months) in a market that started with ChatGPT debuting (2022-11-30) while Claude debuted is dated Q1/2023 (15 months) and DeepSeek in Q1/2025. It is not a matter of perception or time but about the sunk-cost. AI driven fact-check can systematically fail (2025-06-13) is an article which does not go in depth into the LLM design but just analyzes their responses on a set of specific topics. Yet, it presents a quite dark overall picture: there is a lot of woke propaganda embedded into the LLMs training. Because the practice of using other companies' LLM to train faster is quite common despite nobody admitting it — and for those who deny it: some questions have pretty clear similar responses despite many different aspects existing hence different answers — therefore the propaganda propagates. People wonder about AGI but what is about retraining all the LLMs, instead? Or, starting from zero a new architecture with a fresh training plan? This dilemma looks HUGE, indeed. It is not just about the money, it would be the VC business model collapse, they only have one profitabe, currently. Instead Apple's dilemma about restart-or-retrain does not exist because their sunk-cost is zero. What is the advantage of the early birds? Collecting VC funds. What is the advantage of who arrive a bit later, after the hype peak? Learning from the other's mistakes, just paying attention. Continue in this dialogue with ChatGPT or into its transcription epurated by the suggested English corrections.Update 2025-06-21
Today via an X tweet, Elon Musk promised to solve the problem exposed in this article and achieve the rectification of the corpus of human knowledge using the next-to-come a/Grok AI version. Good luck!We will use Grok 3.5 (maybe we should call it 4), which has advanced reasoning, to rewrite the entire corpus of human knowledge, adding missing information and deleting errors. Then retrain on that. Far too much garbage in any foundation model trained on uncorrected data.
Related articles
Share alike
© 2025, Roberto A. Foglietta <roberto.foglietta@gmail.com>, CC BY-NC-ND 4.0